In a previous blog post, I talked about PDX. PDX is a data layout that transposes vectors in a column-major order. This layout unleashes the true potential of dimension pruning algorithms for similarity search.
Since then, we noticed that PDX fell short in certain settings, such as retrieving more than 10 neighbors or when targeting recalls below 0.95. In this blog post, I discuss how we addressed these issues and achieved sub-millisecond similarity search on millions of vectors using only vanilla IVF indexes on the PDX layout. This is remarkable, as vanilla IVF indexes are deemed “slow” by many vector database vendors.
Of course, you can skip the intro and go directly to the benchmarks ;)
Recap: The PDX layout
PDX is a transposed layout (a.k.a. columnar, vertical, or decomposed layout), which means that the same dimension of different vectors are stored sequentially. This decomposition occurs within a block (e.g., a cluster in an IVF index).
The PDX layout unleashes the true potential of pruning algorithms (e.g., ADSampling). The idea of pruning is to avoid checking all the dimensions of a vector to determine if it is a neighbor of a query. PDX is the ideal environment for pruning, as we avoid introducing a control hazard in the core distance calculation kernel to ask whether we can prune a vector. You can read more details about this and other benefits of the PDX layout in my previous blog post.
However, when increasing the number of retrieved neighbors (e.g., K = 100), the pruning threshold loosens. As a result, a higher number of candidates is explored in the pruning phase of the search algorithm, resulting in increased random access in the transposed layout. The same problem occurs when few clusters are explored (e.g., 8 clusters), as the number of candidates in the pruning phase is high.
An improved PDX layout
We have evolved the PDX layout from the one presented in our publication. This new iteration reduces random access and is less impacted by looser pruning thresholds. Hereby, it is more robust and accelerates a wider variety of settings (e.g., K = 100, fewer clusters probed). Furthermore, we adapted the layout to work with smaller data types such as 8-bit and 1-bit vectors.
The key observation for these improvements is that pruning algorithms, such as ADSampling, access dimensions in a sequential order. With this in mind, let’s look at the newer versions of PDX.
float32
For float32, the first 25% of the dimensions are fully decomposed, just as the original PDX. We refer to this as the “vertical block.” The rest (75%) are decomposed into subvectors of 64 dimensions. We refer to this as the “horizontal block.” The vertical block is used for efficient pruning, and the horizontal block is accessed on the candidates that were not pruned. This horizontal block is still decomposed every 64 dimensions. The idea behind this is that we still have a chance to prune the few remaining candidates every 64 dimensions.
The following image shows this layout. Storage is sequential from left to right, and from top to bottom:

With this layout, random access is significantly reduced during the pruning phase of the search, while still benefiting from the adaptiveness per query and dataset provided by the vertical block. Another trick we incorporated into our algorithm is that if the remaining candidates are already low before finishing the scan of the vertical block, we directly jump to the horizontal blocks. As a result, random access of individual dimensions only happens for an extremely low number of vectors.
8 bits
Smaller data types are not friendly to the original PDX, as we must accumulate distances on wider types, resulting in asymmetry. We can work around this by changing the layout. For 8 bits, the vertical block is decomposed every 4 dimensions. This allows us to use dot product instructions (VPDPBUSD in x86 and UDOT/SDOT in NEON) to calculate L2 or IP kernels while still benefiting from PDX. The horizontal block remains decomposed every 64 dimensions.
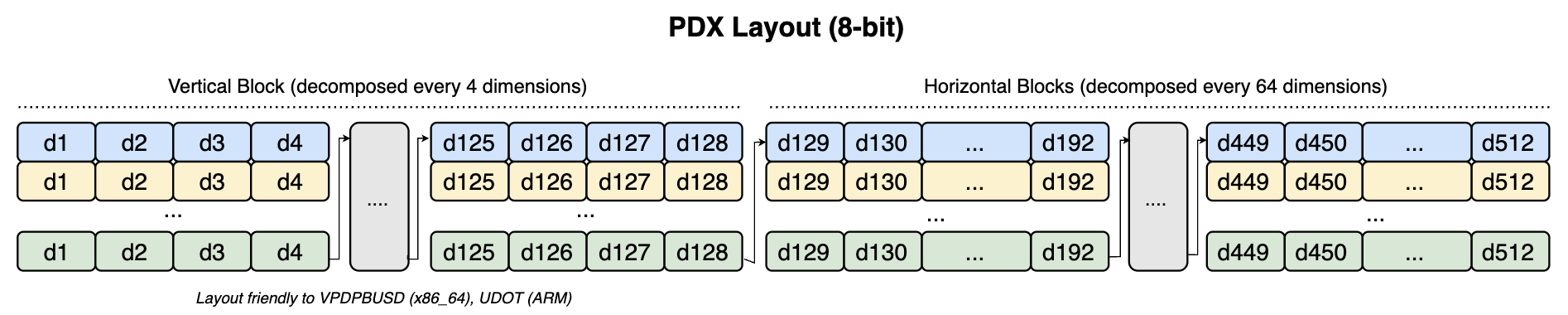
1 bit
For Hamming/Jaccard kernels, we can use a layout decomposed every 8 dimensions (naturally grouped into bytes). The population count accumulation can be done in bytes. If d > 256, we flush the popcounts into a wider type every 32 words. This has not been implemented in our repository yet, but you can find some promising benchmarks here.
Sub-millisecond similarity search with PDX and IVF₂
Finally, we introduce IVF₂, a two-level IVF index that tackles a bottleneck of IVF indexes: finding the nearest centroids. The idea is simple: we cluster the centroids generated from the IVF index. This generates a new reduced set of super-centroids, which we scan first to determine which clusters of centroids are the most promising. Then, PDX can quickly scan these super-clusters which contain the original centroids, without sacrificing recall, thanks to pruning. In brief, we are simply performing a new k-means clustering on the centroids to enable the use of pruning algorithms when scanning them.
This achieves significant throughput improvements when paired with 8-bit quantization. IVF₂ is so fast scanning the vectors that now the bottleneck of our algorithm is the random rotation of the query vector needed for ADSampling. We are planning to improve this in a future release.
Benchmarks
We present single-threaded benchmarks against FAISS on r7iz.xlarge (x86_64, Intel Sapphire Rapids with AVX512) and r8g.xlarge (ARM, Graviton 4 with NEON/SVE) instances. We used 3 datasets:
- OpenAI embeddings: N=1M, D=1536
- MxbAI embeddings: N=769K, D=1024
- arXiv embeddings: N=2.25M, D=768
Two-Level IVF (IVF₂)
IVF₂ can achieve sub-millisecond query latency on both x86 and ARM, accelerating SIMD-optimized FAISS by factors ranging from 2x to 13x, depending on the target recall.
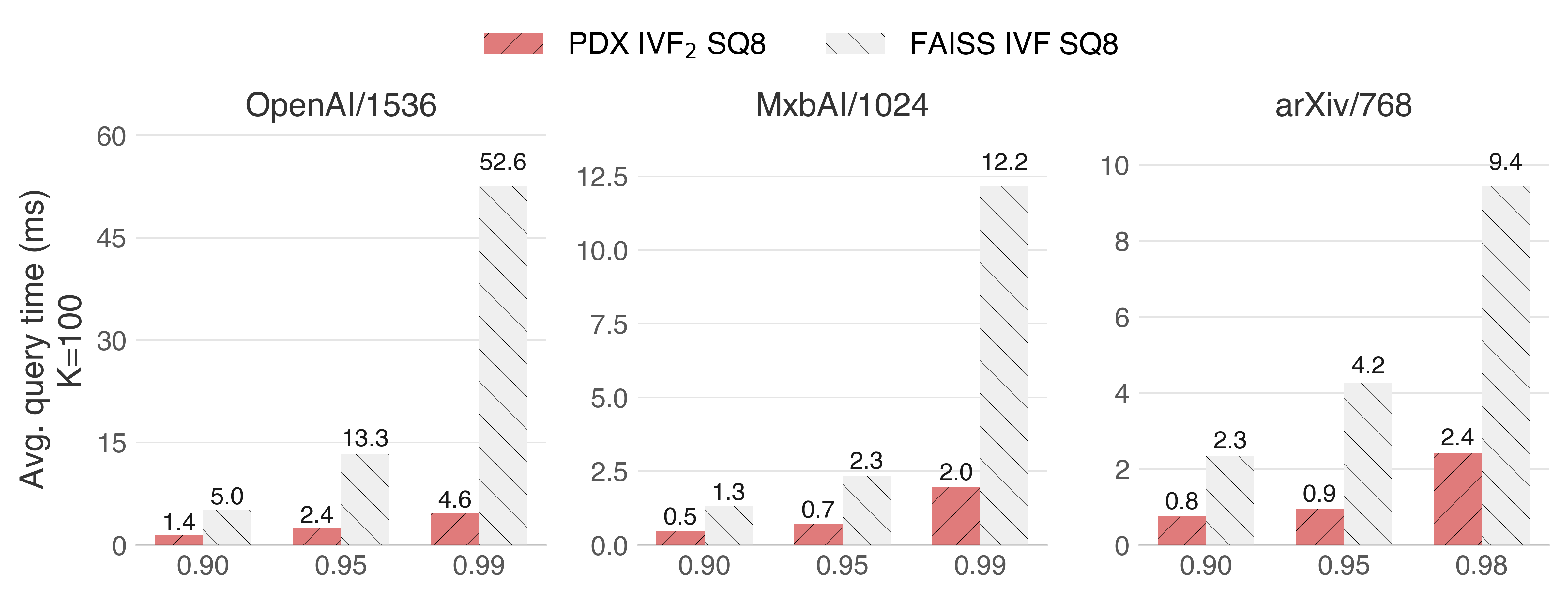
Intel Sapphire Rapids (x86_64 with AVX512)
In the OpenAI dataset at 0.90, the random rotation of the query vector dominates the runtime. Therefore, we may also achieve sub-millisecond performance here by improving the random rotation of the query with a faster algorithm.
A key factor for these speedups is that we do not decode the data to the float32 domain. Instead, we transform the query into the 8-bit domain and perform the distance calculation using 8-bit SIMD.
In ARM, things get uglier for FAISS as they lack SIMD for 8-bit decoding into float32:
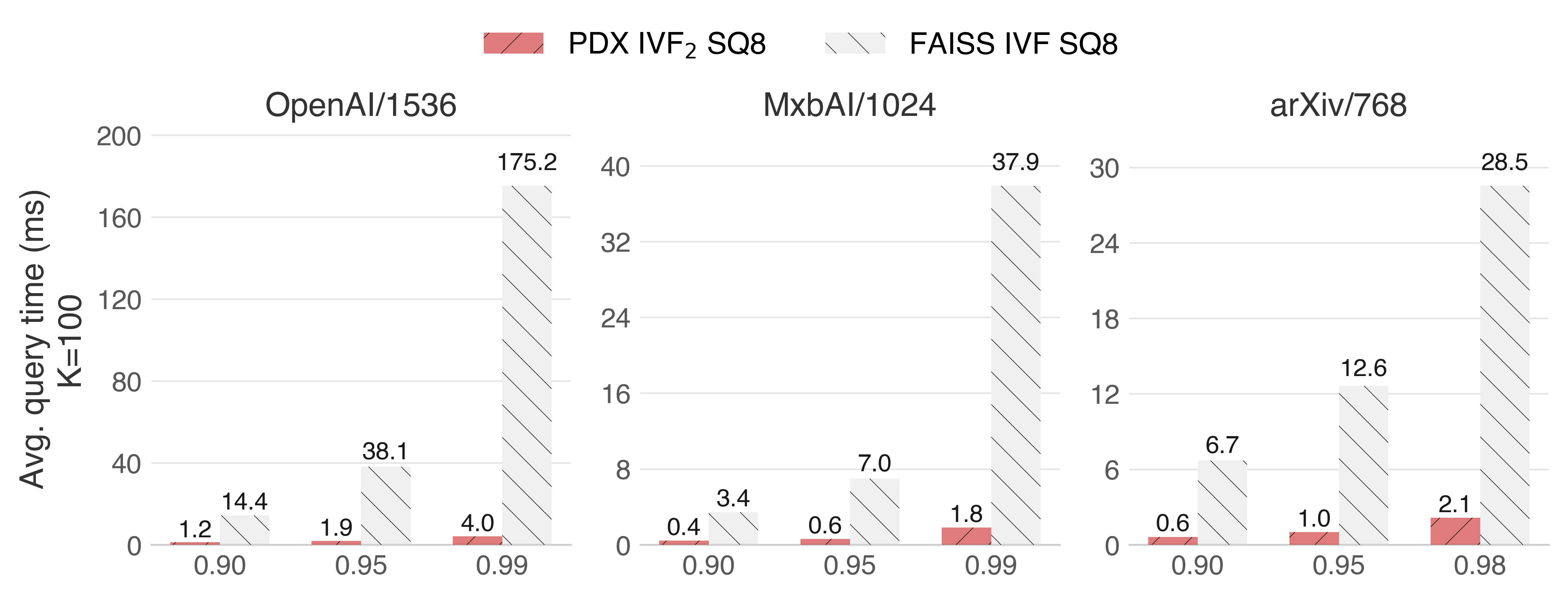
Graviton 4 (ARM with NEON)
Vanilla IVF
In vanilla IVF indexes with float32 vectors, PDX demonstrates its superiority, now even with a larger number of neighbors:
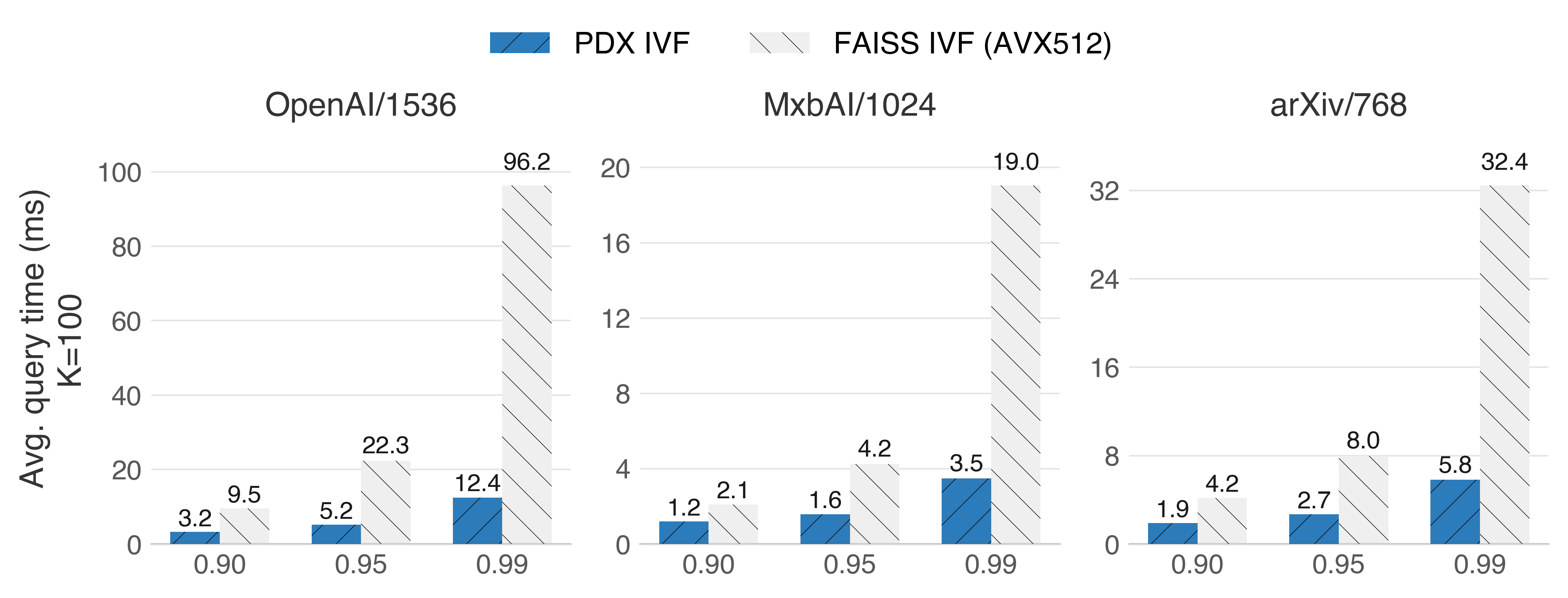
Intel Sapphire Rapids (x86_64 with AVX512)
While still maintaining its superiority with a smaller number of neighbors (K=10):
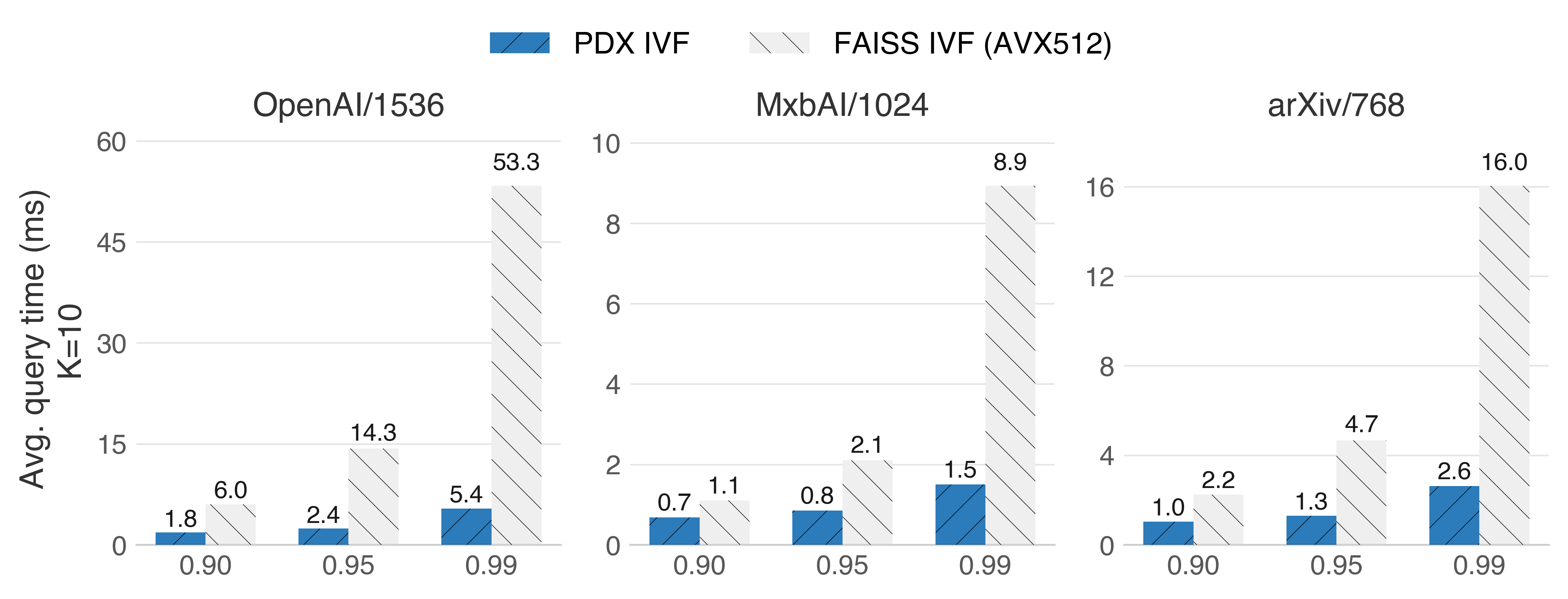
Intel Sapphire Rapids (x86_64 with AVX512)
Exhaustive search + IVF
An exhaustive search scans all the vectors in the collection. Having an IVF index with PDX can EXTREMELY accelerate this without sacrificing recall, thanks to the reliable pruning of ADSampling. We can accelerate a complete scan of the collection up to 50x!
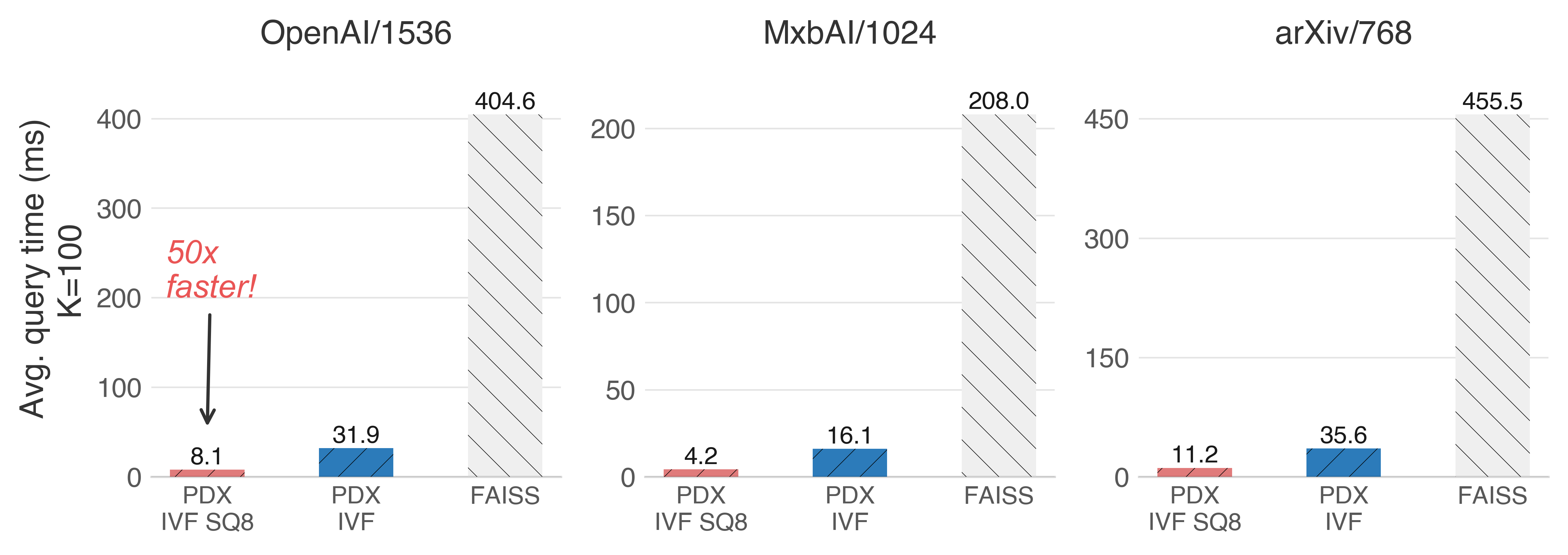
Intel Sapphire Rapids (x86_64 with AVX512)
The key observation here is that, thanks to the underlying IVF index, the exhaustive search starts with the most promising clusters. A tight threshold is found early on, which enables the quick pruning of most candidates.
Note that, on these datasets, the exhaustive search with SQ8 (8-bit quantization) achieves > 0.9999 recall.
What’s next?
We think PDX performance is remarkable, given that, at its core, it is a vanilla IVF index with traditional scalar quantization. The latter means that we can achieve sub-millisecond similarity search alongside all the benefits of IVF indexes: a low memory footprint and low construction times.
For now, improving the random rotation algorithm is key to further reducing query latency. The RaBitQ-Library already proposes an alternative with an O(nlog(n)) complexity, in contrast to the vanilla rotation, which has an O(N^2) complexity.
We will soon add PDX to the VIBE benchmark. So, stay tuned!
Ps. At CWI, we are currently looking for MSc. students to help us develop PDX! If you are interested in PDX and are looking for thesis projects, reach out at [email protected]